
· cloud
Prometheus分区实践
背景
单个 Prometheus Server 可以轻松的处理数以百万的时间序列。但当机器规模过大时,需要对其进行分区,Prometheus 也提供了集群联邦的功能,方便对其扩展。
我们采用 Prometheus 来监控 k8s 集群,节点数 400,采集的 samples 是 280w,Prometheus 官方的显示每秒可抓取 10w samples。当集群规模扩大到上千节点时,单个 Prometheus 不足以处理大量数据,需要对其进行分区。
可以根据
scrape_samples_scraped{job=${JOBNAME}}来统计各个 job 的 samples 数目 可以根据count({__name__=~".*:.*"})来统计 metrics 总数
集群联邦
在 Promehtues 的源码中,federate联邦功能在web中,是一个特殊的查询接口,允许一个 prometheus 抓取另一个 prometheus 的 metrics
可以通过全局的 prometheus 抓取其他 slave prometheus 从而达到分区的目的 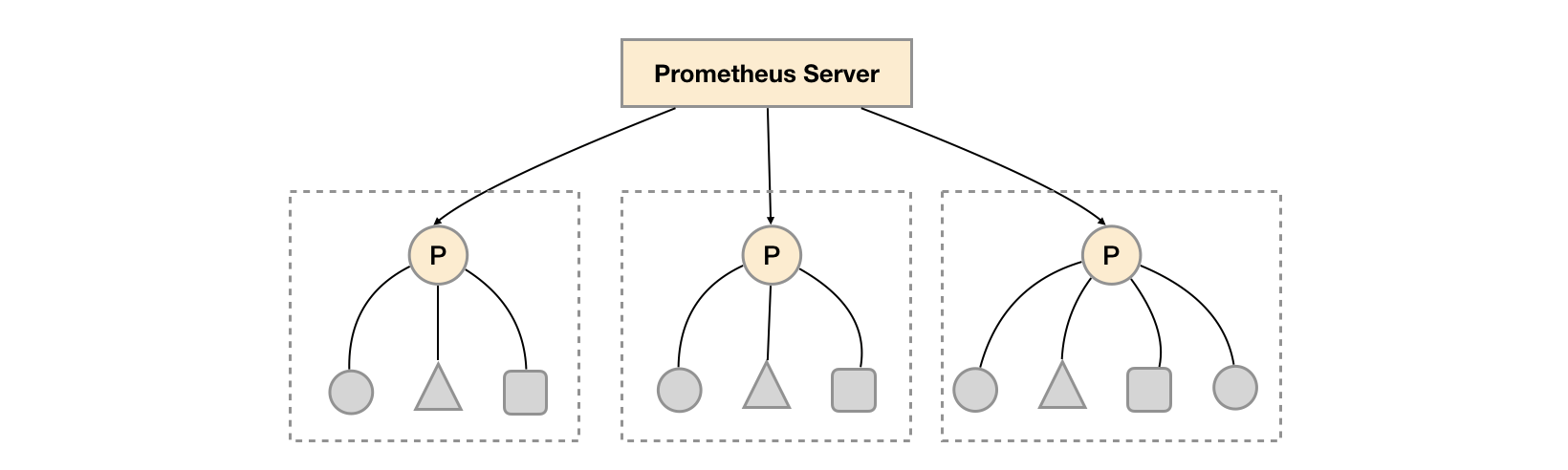
使用 federate 进行分区通过有两种方式
功能分区
每个模块为一个分区,如 node-exporter 为一个分区,kube-state-metrics 为一个分区,再使用全局的 Prometheus 汇总 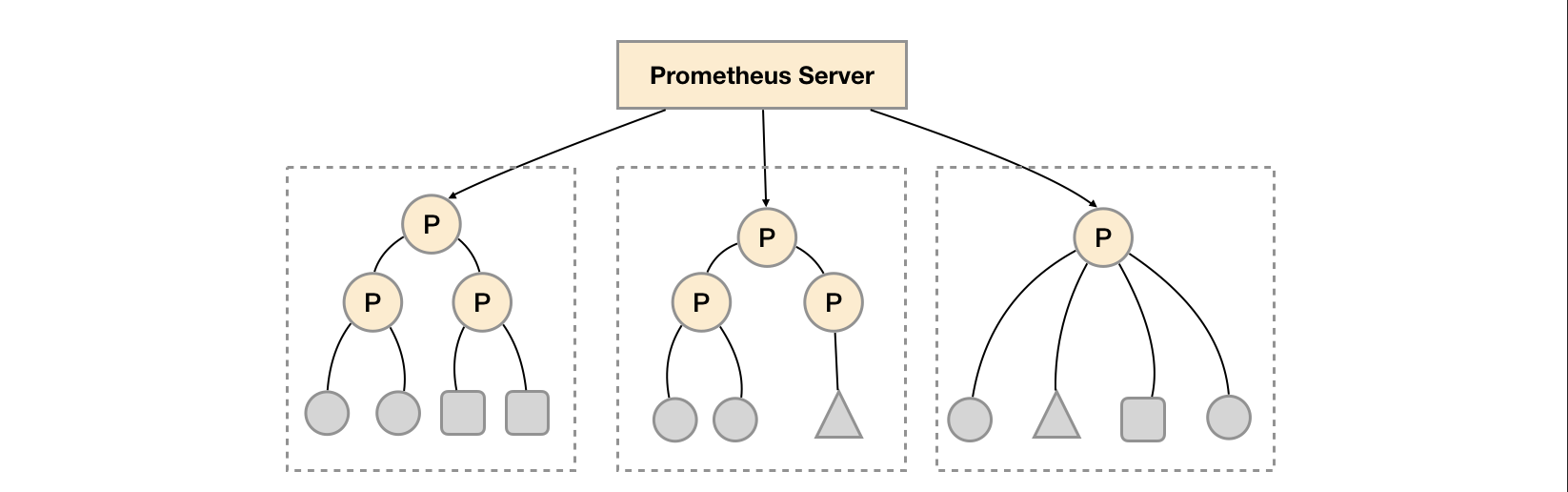
实现简单,但当单个 job 采集任务过大(如 node-exporter)时,单个 Prometheus slave 也会成为瓶颈
水平扩展
针对功能分区的不足,将同一任务的不同实例的监控数据采集任务划分到不同的 Prometheus 实例。通过 relabel 设置,我们可以确保当前 Prometheus Server 只收集当前采集任务的一部分实例的监控指标。 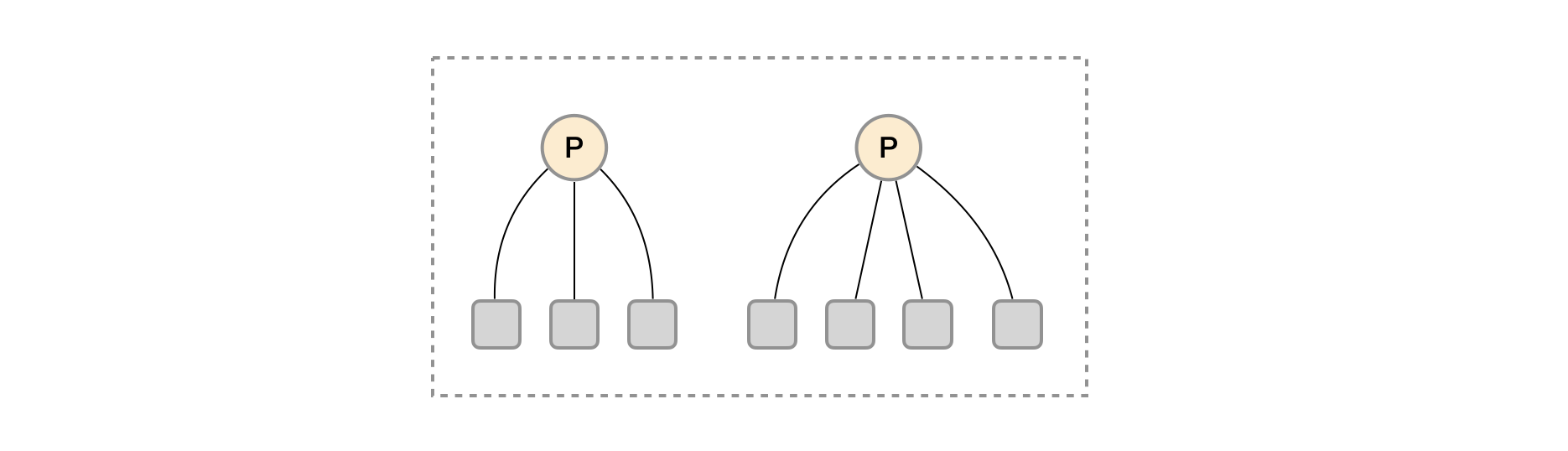
下为官方提供的配置
global:
external_labels:
slave: 1 # This is the 2nd slave. This prevents clashes between slaves.
scrape_configs:
- job_name: some_job
# Add usual service discovery here, such as static_configs
relabel_configs:
- source_labels: [__address__]
modulus: 4 # 4 slaves
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^1$ # This is the 2nd slave
action: keep
并且通过当前数据中心的一个中心 Prometheus Server 将监控数据进行聚合到任务级别。
- scrape_config:
- job_name: slaves
honor_labels: true
metrics_path: /federate
params:
match[]:
- '{__name__=~"^slave:.*"}' # Request all slave-level time series
static_configs:
- targets:
- slave0:9090
- slave1:9090
- slave3:9090
- slave4:9090
水平扩展,即通过联邦集群的特性在任务的实例级别对 Prometheus 采集任务进行划分,以支持规模的扩展。
我们的方案
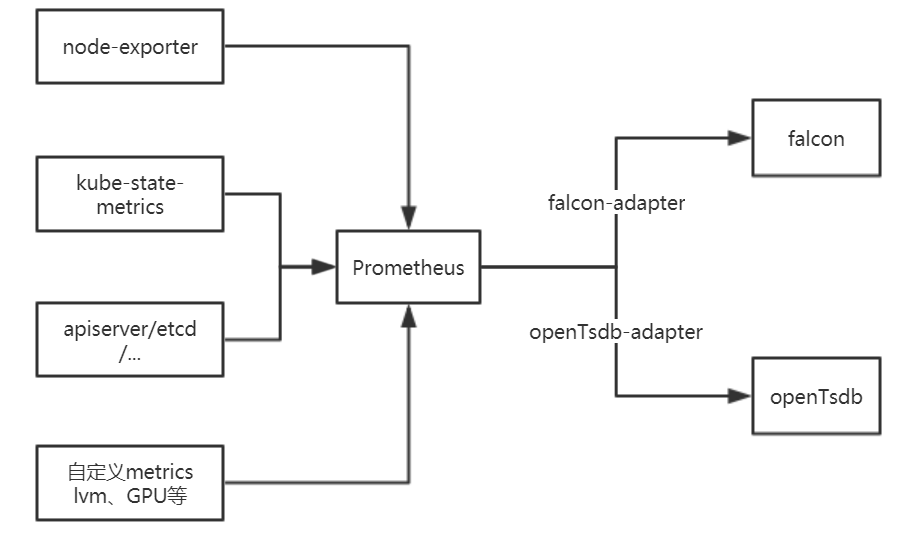
整体架构
- Promehtues 以容器化的方式部署在 k8s 集群中
- 收集 node-exporter、cadvisor、kubelet、kube-state-metrics、k8s 核心组件、自定义 metrics
- 通过实现 opentsdb-adapter,对监控数据做持久化
- 通过 falcon-adapter,为监控数据提供报警
分区方案
- Prometheus 分区包括 master Prometheus 与 slave Promehtues
- 我们将监控数据分为多个层次: cluster, namespace, deployment/daemonset, pod, node
- 由于 kubelet, node-exporter, cadvisor 等是以 node 为单位采集的,所以安装 node 节点来划分不同 job
- slave Prometheus 按照 node 切片采集 node,pod 级别数据
- kube-state-metrics 暂时无法切片,可通过 replicaset 设置多个,单独作为一个 kube-state Prometheus,供其他 slave Prometheus 采集
- 其他 etcd, apiserver 等自定义组件可通过 master Promehtues 直接采集
整体架构如下 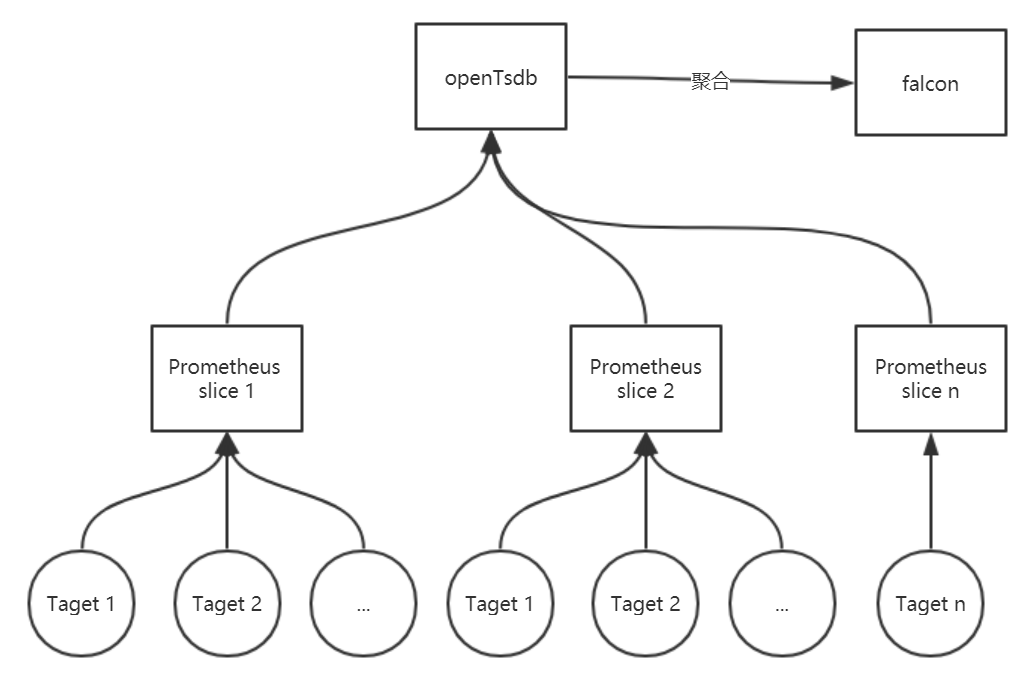
master Prometheus 配置
global:
scrape_interval: 60s
scrape_timeout: 30s
evaluation_interval: 60s
external_labels:
cluster: { { CLUSTER } }
production_environment: { { ENV } }
rule_files:
- cluster.yml
- namespace.yml
- deployment.yml
- daemonset.yml
scrape_configs:
- job_name: federate-slave
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{__name__=~"pod:.*|node:.*"}'
kubernetes_sd_configs:
- role: pod
namespaces:
names:
- kube-system
relabel_configs:
- source_labels:
- __meta_kubernetes_pod_label_app
action: keep
regex: prometheus-slave.*
- source_labels:
- __meta_kubernetes_pod_container_port_number
action: keep
regex: 9090
- job_name: federate-kubestate
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{__name__=~"deployment:.*|daemonset:.*"}'
kubernetes_sd_configs:
- role: pod
namespaces:
names:
- kube-system
relabel_configs:
- source_labels:
- __meta_kubernetes_pod_label_app
action: keep
regex: prometheus-kubestate.*
- source_labels:
- __meta_kubernetes_pod_container_port_number
action: keep
regex: 9090
slave Prometheus 配置
global:
scrape_interval: 60s
scrape_timeout: 30s
evaluation_interval: 60s
external_labels:
cluster: { { CLUSTER } }
production_environment: { { ENV } }
rule_files:
- node.yml
- pod.yml
scrape_configs:
- job_name: federate-kubestate
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{__name__=~"pod:.*|node:.*"}'
kubernetes_sd_configs:
- role: pod
namespaces:
names:
- kube-system
relabel_configs:
- source_labels:
- __meta_kubernetes_pod_label_app
action: keep
regex: prometheus-kubestate.*
- source_labels:
- __meta_kubernetes_pod_container_port_number
action: keep
regex: 9090
metric_relabel_configs:
- source_labels: [node]
modulus: { { MODULES } }
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: { { SLAVEID } }
action: keep
- job_name: kubelet
scheme: https
kubernetes_sd_configs:
- role: node
namespaces:
names: []
tls_config:
insecure_skip_verify: true
relabel_configs:
- source_labels: []
regex: __meta_kubernetes_node_label_(.+)
replacement: '$1'
action: labelmap
- source_labels: [__meta_kubernetes_node_label_kubernetes_io_hostname]
modulus: { { MODULES } }
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: { { SLAVEID } }
action: keep
- job_name: ...
可能的问题
- 如何部署,配置复杂,现在采用 shell 脚本加 kustomize,是否有更简单的方法
- 分区的动态扩展随着 node 的规模
- kube-state-metrics 是否会成为瓶颈,目前的kube-state-metrics 性能测试
- 由于分区同一个 job 的不同 instance 采集的时间有偏差,对聚合有一定影响
- 可靠性保证,如果一个或多个 slave 的挂了如何处理,使用 k8s 来保证 prometheus 的可用性是否可靠