
· ai
图解RAG
RAG(Retrieval-Augmented Generation, 检索增强生成)是一种将信息检索与生成模型结合的方法,也是企业落地大模型应用最常见的方式。
什么是RAG
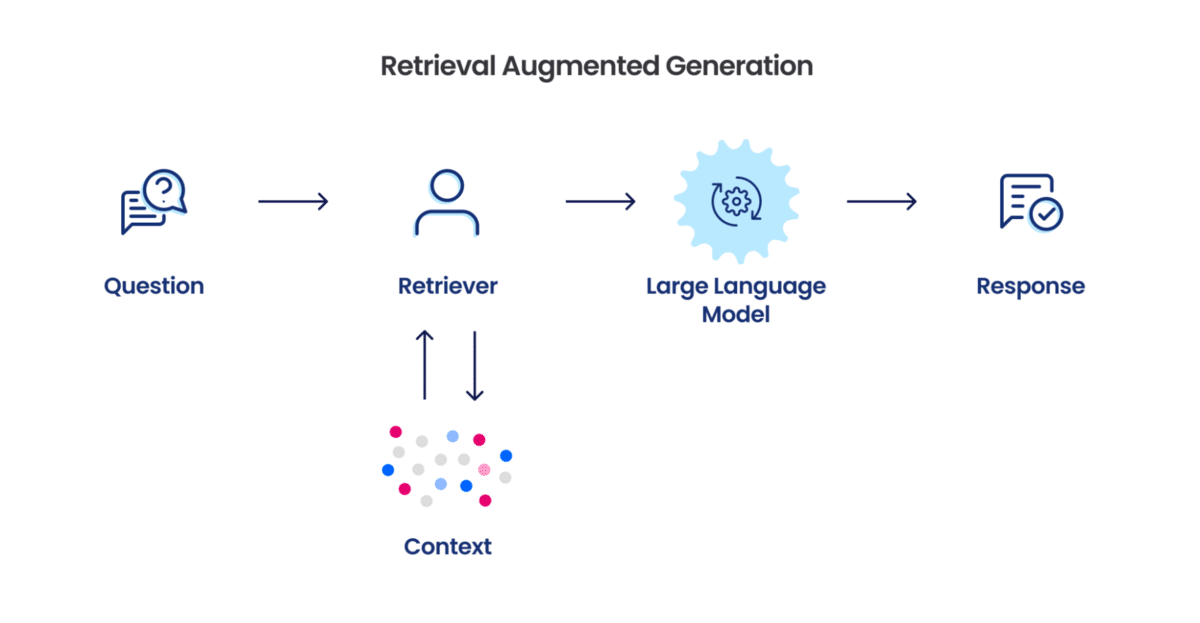
RAG接受用户输入,从一个大型文档集合中检索相关信息,然后将用户问题与检索信息发送到大模型,大模型生成最终答案。
RAG可以借助外部知识源,从而提升回答的准确性和信息丰富度,相当于为LLM配置了一个书架,虽然有些知识不知道,但可以参考相关书籍从而获取不错的答案。可以用来做文档问答系统、客服系统、企业内私有数据的问答系统。
工作原理
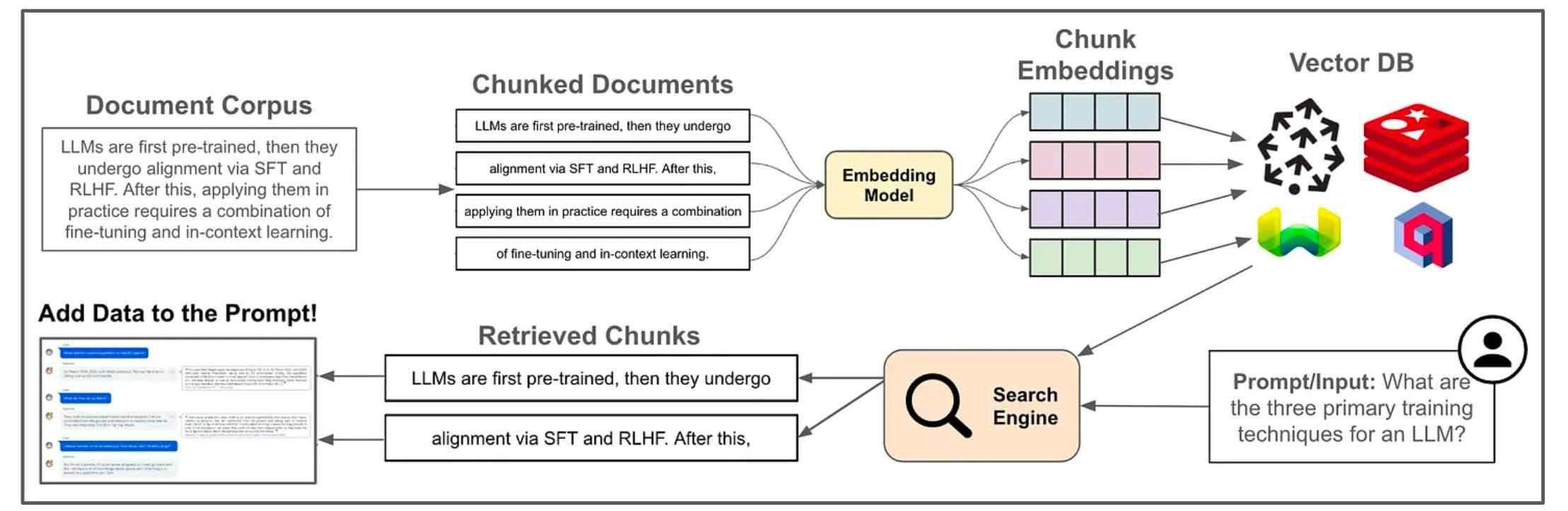
基础RAG分为三个阶段Indexing、Retrieval与Generation:
- Indexing
- 将知识库拆分成固定大小的块
- 选择合适的
Embedding模型将数据块向量化,存放在VectorDB(向量数据库)中
- Retrieval
- 当用户查询时,先将查询转换为向量
- 然后在
VectorDB中匹配相关内容
- Generation
- 将用户输入与检索信息填入Prompt发送给大模型
- 大模型返回结果
RAG范式
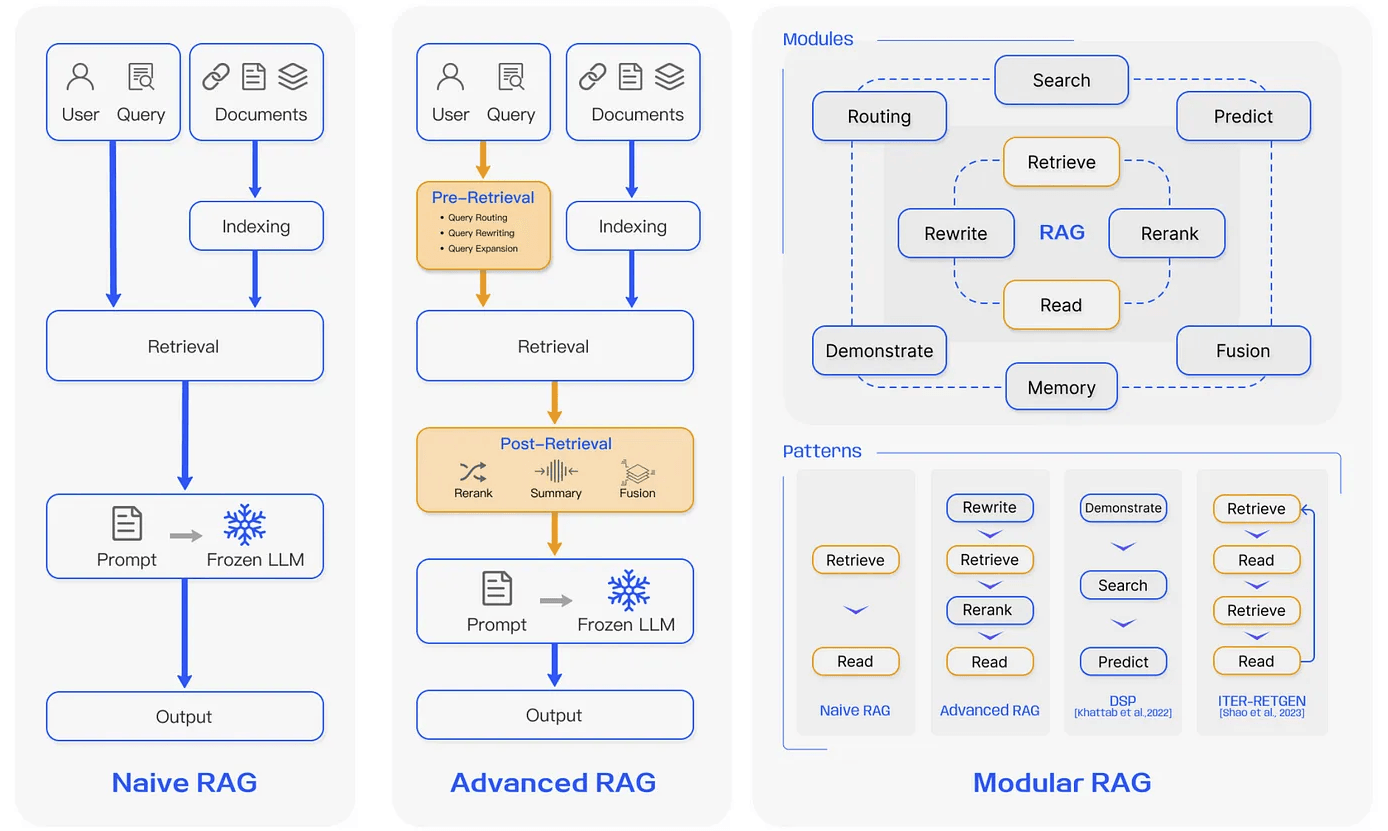
RAG应用根据复杂程度可分为三类:
- Naive RAG(朴素RAG)
- Advanced RAG(高级RAG)
- Modular RAG(模块化RAG)
Naive RAG
Naive RAG遵循传统的RAG索引、检索和生成过程。简而言之,用户输入用于查询相关文档,然后这些文档与提示相结合并传递给模型以生成最终响应。如果应用程序涉及多轮对话交互,则可以将对话历史集成到提示中。
Naive RAG实现简单但有一些局限性,例如精度低(没有检索到相关片段)、召回率低(未能检索到所有相关片段)。
Advanced RAG
Advanced RAG在Naive RAG的基础上,通过一些技术手段提高了检索质量,涉及优化预检索、检索和后检索过程。
- 预检索优化了数据索引过程,方法包括:增强数据粒度、优化索引结构、添加元数据等。
- 检索中旨在提高检索的准确性,常见方法有:查询重写、多路召回、优化嵌入模型等。
- 检索后通过检查重排(Rerank)、上下文压缩等。
Modular RAG
Modular RAG整合了Advanced RAG的各种模块和技术,以改善整体的RAG系统。包括搜索、路由、内存、融合等模块,朴素RAG与高级RAG只是其中的特例。
RAG框架
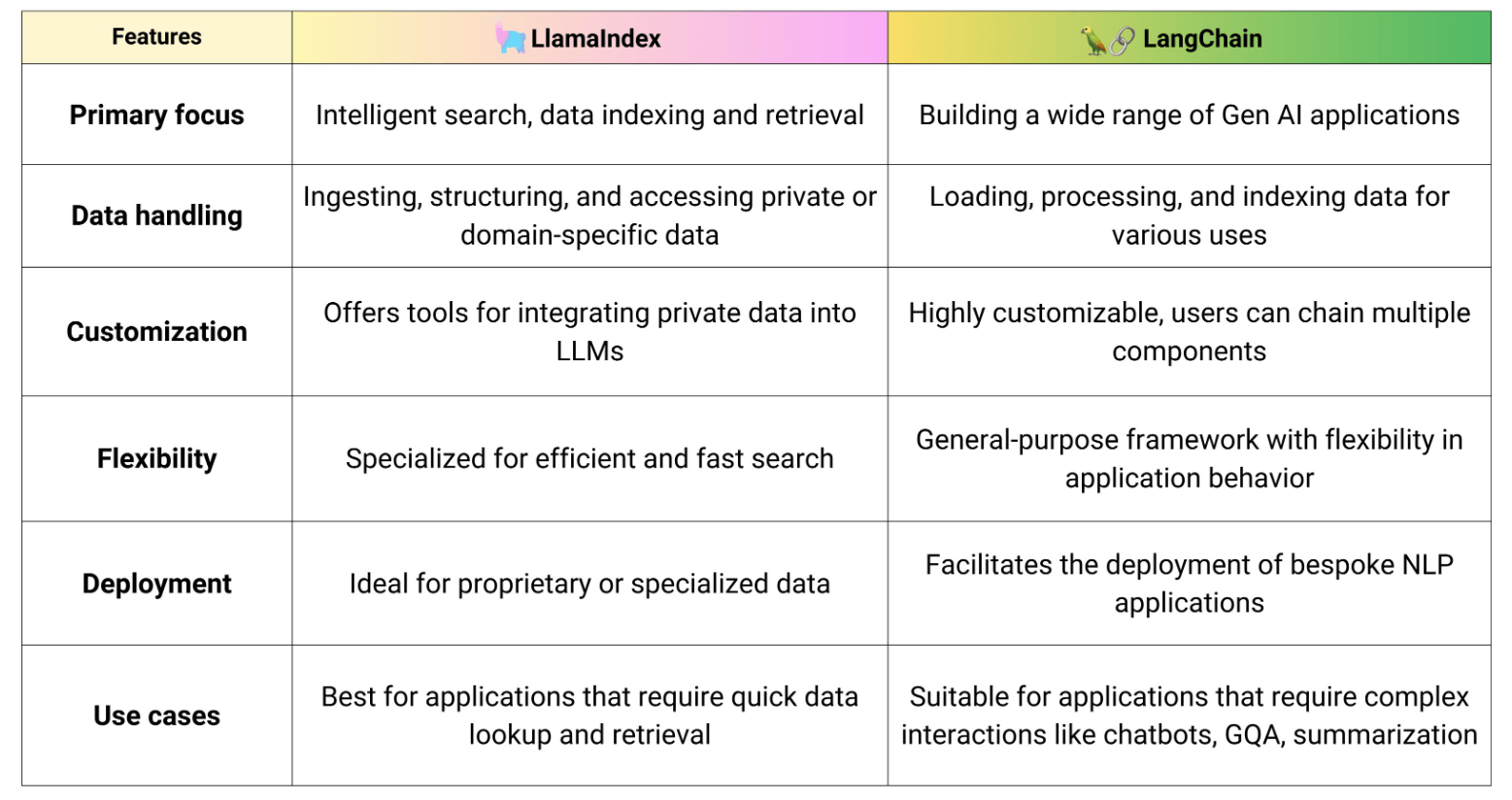
目前比较流行的RAG框架有LlamaIndex与LangChain,可以根据使用场景选择合适的框架,当然这些框架也在不断发展。
LlamaIndex是一个构建大模型应用的数据框架,从名字可以看出专注于大模型应用数据处理,比如加载、索引、查询等。LangChain是一个通用的大模型应用开发框架,使用模块化设计方便开发人员构建大模型应用,比如问答系统、智能客服、智能代理等。
RAG评估
RAG应用的流程较长,每一步都会影响到最终效果,那么怎么知道我的RAG应用哪里需要优化呢?这就需要用到RAG评估。
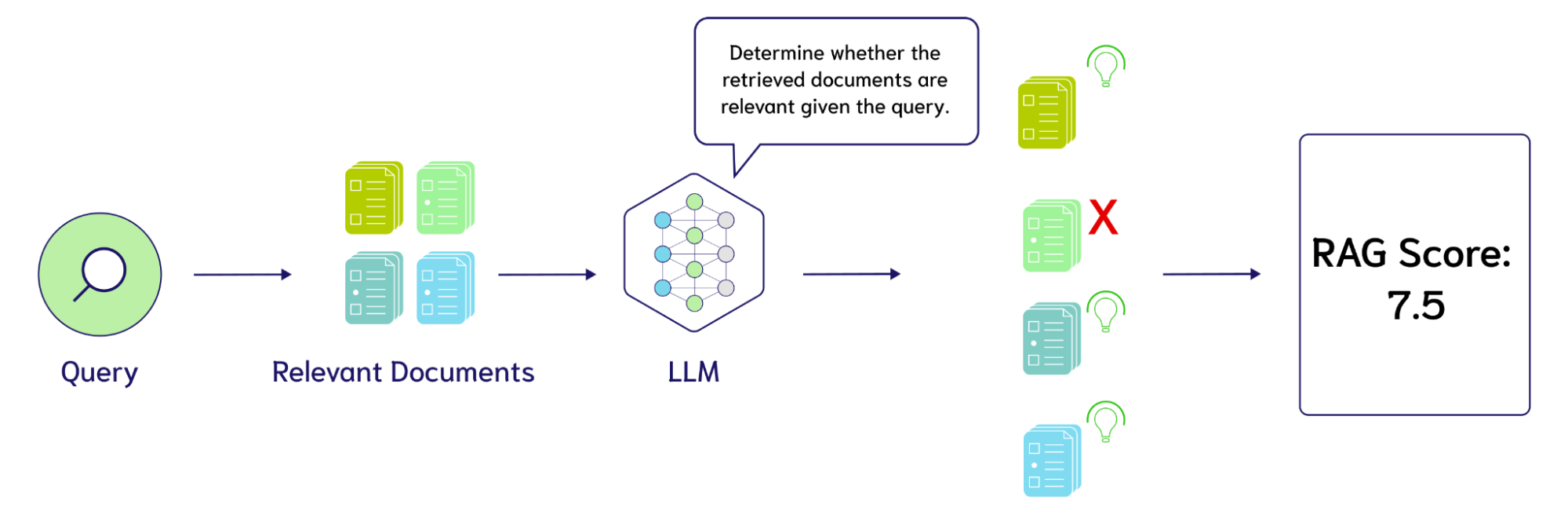
通过设置一些指标,常见的如Correctness(答案准确性)、Answer Relevancy(答案相关性)、Faithfulness(忠诚度)、Context Precision(上下文精度)等,来评估应用各个阶段的表现情况,可以人工打分也可以借助LLM来实现,根据打分结果来做对应的优化。
总结
本文总结了RAG应用的相关内容,包括原理、开发范式、常用框架以及评估等。当然RAG应用还面临了不少挑战,随着LLM的快速发展,RAG必定也会推陈出新。
Explore more in https://qingwave.github.io