
· ai
大模型时代
随着ChatGPT的出圈,基于大模型开发的应用也不断涌现,不管是不是相关方向的从业人员,在这一年多总能听到很多新名词,从LLM、Prompt、RAG到Fine-tuning、Agent,各个大企业都在讲All in AI,一些技术会议也明显感觉到AI占用的篇幅越来越多。
无论企业还是个人,好像不使用大模型就落伍了,更甚者我们会不会被AI取代,最近听到一种说法挺认同的:
AI不会取代人类,只是会用AI的人会取代不会用的
AI或者说大模型是不是正在掀起一场新的工业革命,我不好说,但大模型的影响力比以往近10年产生的新技术都大,譬如区块链、Web3、云原生,所有行业都值得用大模型重新做一遍,上一次有这个待遇的还是互联网,之前常说互联网+,那么现在是不是到了AI+的时代。
人生又能遇到几次这样的浪潮,在大模型时代,我们要怎么做呢?
我的大模型之路
22年12月,ChatGPT横空出世,当时注册卡的很严,借了个账号体验体验,感觉回答的很像真人,比以往所谓的语音助手要好很多,但仅此而已,还没有很深刻的体会。
23年开始尝试用New Bing来解决工作中遇到的问题,确实比搜索引擎体验好很多。后来趁着出国度假申请了ChatGPT的账号,工作基本是离不开它了,让它来写代码、替代搜索引擎、文章润色。也尝试过其他Github Copilot、LLama3、千问等等,各种LLM发布时号称怎么怎么打败OpenAI,到头来发现还是ChatGPT最好用。
23年底,公司组织了AI相关的竞赛,借机开始研究怎么基于大模型(LLM)做开发,当时基于llama-index开发了一个RAG+自动执行的小应用。后来也开始不断地了解相关知识,LangChain、Agent等。
接触的越多越发觉得大模型太厉害了,能解决以往不敢想象的事情,虽然还有很多局限性。那么作为开发者,怎么样才能更好地利用大模型呢?
大模型的能力
如果我们要使用一种技术,必须能清晰地了解这种技术的边界。那么大模型能做什么,不能做什么?
LLM能做的事
- 自然语言的理解和生成,可以理解并生成文本、代码生成、摘要等
- 多语言支持,在多种语言间进行转换,翻译、代码转换等
- 简单的推理,能够进行一定程度的逻辑推理,如情感识别、问答、修复Bug
- 多模态的能力,识别图像、语言等
LLM的局限
- 幻觉,倒不如说是大模型的特性,大模型给出的答案可能不准确也不可靠,不能使用的在医疗等准确度要求较高的场景
- 推理能力有限,对于复杂任务效果不好
- 深层次的上下文理解,大模型在需要深层次上下文理解或常识推理的任务中仍会遇到困难
- 数据的准确性与时效性,大模型本身的训练数据可能会含有一些脏数据、政治倾向等,也不包含最新的实时数据
- 物理世界的操作,无法执行外部动作,比如帮你取快递、感知环境
- 创造性思维,虽然大模型能够生成新颖的内容,但内容都是基于训练数据的,并不是真的创新思考
尽管当前大模型有一些局限,但是随着技术的发展,大模型本身的能力也在不断发展。
大模型开发
我不是专业的LLM开发者,抛开底层的技术和优化(Pre-Training, Fine-Tuning等),基于大模型的应用开发可分为以下几个级别:
| 级别 | 技术 | 解释 | 应用 |
|---|---|---|---|
| L0:无AI | Code | 根据经验形成代码 | 计算器软件,报表系统 |
| L1:Prompt | LLM + Prompt | 通过合适提示词得到想要的结果,如Few-Shot、COT | 对话机器人,日报生成,小红书模板 |
| L2:RAG | LLM + Prompt + VectorDB | 通过嵌入外部相关数据发送给LLM,得到更准确的回答 | 企业问答系统,智能客服 |
| L3:Workflow | (LLM + Prompt) * Workflow | 组织多个LLM链实现更复杂的应用,如LangChain Chain | 报表分析、意图识别 |
| L4:Agent | LLM + Reflection + Tools + Memory | 智能体可以借助外部工具自动地执行人类布置的多步骤复杂任务,如MetaGPT | 自动故障处理、私人助理 |
| L5:Autonomous Agents | Agents + Awareness + Collaboration | 超级智能体可以感知环境,自动做出决策,并可以与其他智能体协作 | 斯坦福小镇 |
类似自动驾驶的分类级别,根据用户参考程度不同,从L0用户全程参与到L5完全不需要用户参与,中间包含有提示词工程Prompt、RAG应用、基于工作流的LLM应用、AI智能体。
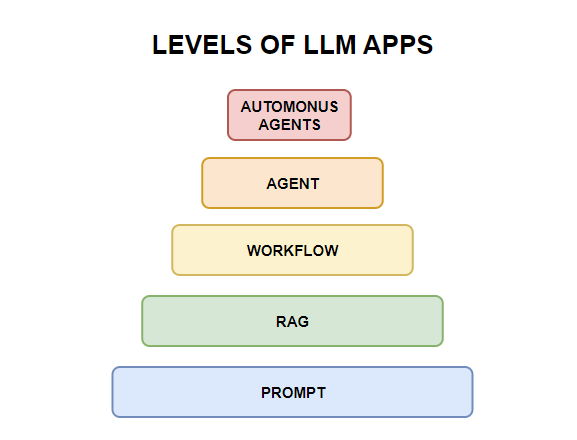
往靠近底层,实现的功能简单,越往上层自动化程度更高,实现的应用越复杂,上层应用可以使用下层的技术,比如Agent一般都会结合RAG、Prompt等,可以根据自己的需求使用场景,选择合适的应用。
Prompt
Prompt即提示词工程,是指大模型提供的输入提示,用来引导LLM生成特定的输出。通过设计不同的提示,可以控制模型生成的内容和行为。
通常我们使用大模型的路径如下:
INPUT -> LLM -> OUTPUT + %
提供一个输入,大模型会给出一个带有随机性的输出,怎么样使得这个输出更符合我们的要求呢,那就需要一定技巧的提示词。
不是所有输入都是Prompt,只有携带系统指令的问题才是。比如
hi, how are you这不是提示词,而answer my question use chinese, question: 'how are you'包含了指令和问题,其中的前面的指令才算作Prompt。
通过Prompt可以让大模型输出特定的内容,比如生成小红书的爆款文案、返回JSON格式、生成工作日报等等。
技术
Prompt有很多类型,比如Zero-Shot(无样本提示词)、Few-Shot(少样本提示词)、COT(思维链,可以实现一些较复杂的推理,数学计算等),更多的可以参考Prompt Engineering。
示例
下面是一个简单Few-Shot例子:
---
Prompt: 你是一个情感识别专家,根据用户的输入,判断句子是"消极"还是"积极",下面是一些例子:
这场比赛好极了! // 积极
今天天气热死了 // 消极
这个电影真难看 // 消极
樊振东好样的 //
---
LLM: 积极
---
局限
- 依赖大模型本身的功能,只能实现相对简单的应用
- 基于提示词的应用很难形成壁垒,通过特定手段可以获取到应用的提示词
RAG
RAG(Retrieval-Augmented Generation, 检索增强生成)是一种将信息检索与生成模型结合的方法。首先根据用户输入从一个大型文档集合中检索相关信息,然后将用户问题与检索信息发送到大模型,大模型生成对应答案。
RAG可以借助外部知识源,从而提升回答的准确性和信息丰富度,相当于为LLM配置了一个书架,虽然有些知识不知道,但可以参考相关书籍从而获取不错的答案。可以用来做文档问答系统、客服系统、企业内私有数据的问答系统。
技术
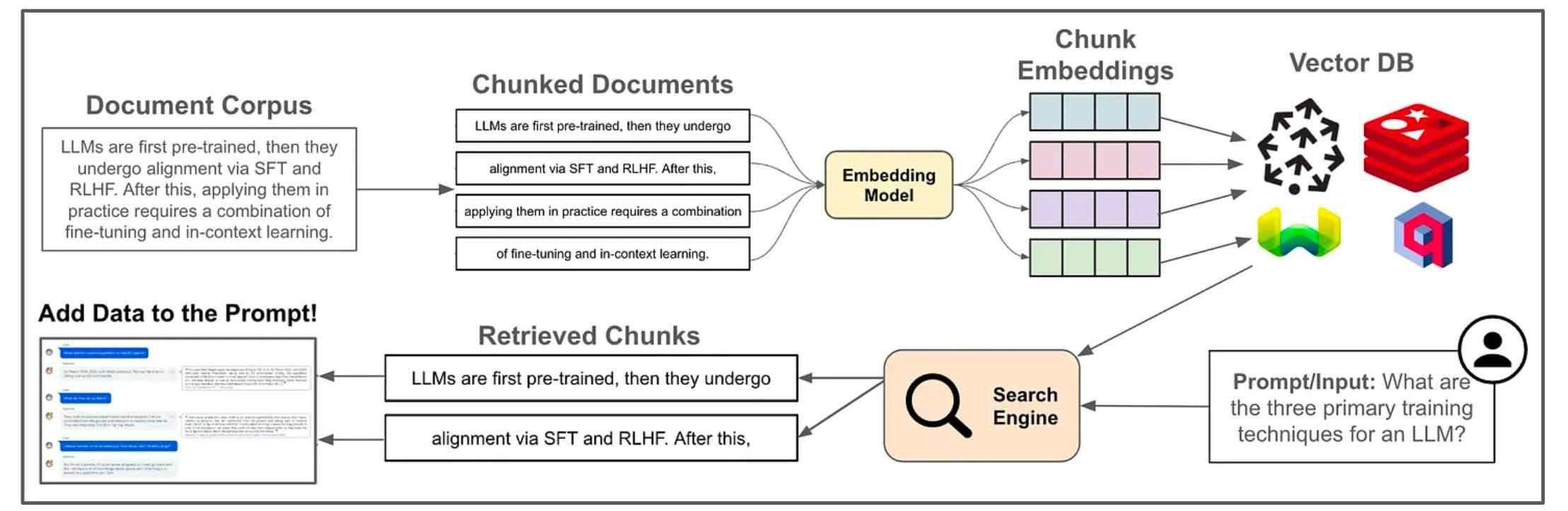
实现一个基础的RAG应用,如上图所示,一般包含如下步骤:
- 将知识库拆分成固定大小的块
- 选择合适的
Embedding模型将数据块向量化,存放在VectorDB(向量数据库)中 - 用户查询时,在VectorDB中匹配相关内容
- 将用户输入与检索信息发送给大模型
- 大模型整理后返回结果
图中也展示一些知识来提升RAG的效果,比如:
- 混合搜索,通过多路召回,综合VectorDB、DB与其他数据源中的数据以提升回答的准确性
- 数据清洗,
RAG应用的效果依赖于高质量的数据 - 效果评估,引入评估系统
借助llama-index与LangChain等工具,可以方便地实现RAG应用。
与Fine-tuning的区别
在使用中,RAG经常会与Fine-tuning(微调)做比较。
RAG可以借助外部数据集,通过检索数据发送给大模型以提升回答效果,大模型本身不知道这些外部知识。RAG成本更低,适合频繁更新的场景,新闻摘要、实时回答等。Fine-tuning是在较小的数据集上继续训练大模型,使其参数更好地适应任务需求。有助于模型理解任务的细微差别,通常用于情感分析、法律文档分析和医学报告生成等需要特定领域术语和风格的任务。微调的上限更高,成本也更高,但不适合频繁更新数据的场景。
两者并不互斥,可以结合一起以实现更好的效果。
局限
- 检索相关性,检索的相关性直接影响最终的效果,通过向量检索来匹配
TopK内容,比如问你吃了吗,正确的应该是去搜索我吃了...而不是直接搜索问题 - 汇总信息,无法进行对比和汇总,比如分析近10天关于AI的新闻
- Token限制,每个LLM都有Token数限制,一些长上下文可能无法全量发送给LLM
Workflow
对于一些复杂任务,LLM并不能很好处理,可以将这些任务拆分成多个步骤,每个步骤使用LLM实现一个简单的任务,将这些任务串起来便是Workflow。
比如可以实现一个歌词应用,拆分为作词与评论,作词链只负责作词,根据用户输入输出对应的歌词;评论家负责评论歌词内容提出建议。
INPUT -> [LYRICIST CHAIN(LLM) ] -> LYRIC -> [REVIEWER CHAIN(LLM)] -> OUTPUT
技术
Workflow是将复杂任务分解为更小的、可管理的单元,结合LLM实现一个多步骤的复杂任务。可以是链式的、或者更复杂的有向无环图。比如LangChain的名字本身就指的是大模型链,其中的SimpleSequentialChain就是顺序调用链、RouterChain路由链,可以动态选择下一个路径形成更复杂的工作流。
局限
- 工作流的调用关系在代码中是写死的,无法灵活处理,只适合特定任务
- 误差累积,初期步骤的错误可能导致执行失败
- 上下文丢失,链条过长造成上下文模糊甚至丢失
Agent
Agent本意是代理人,比如房屋中介,能代替人做部分事情。具体到LLM Agent目前没有一个统一的定义,常翻译为智能体,通常指能够能够感知环境、进行决策并执行动作的智能实体。
技术
下图是一个Agent认可较广的架构,来源于OPENAI的lilianweng: 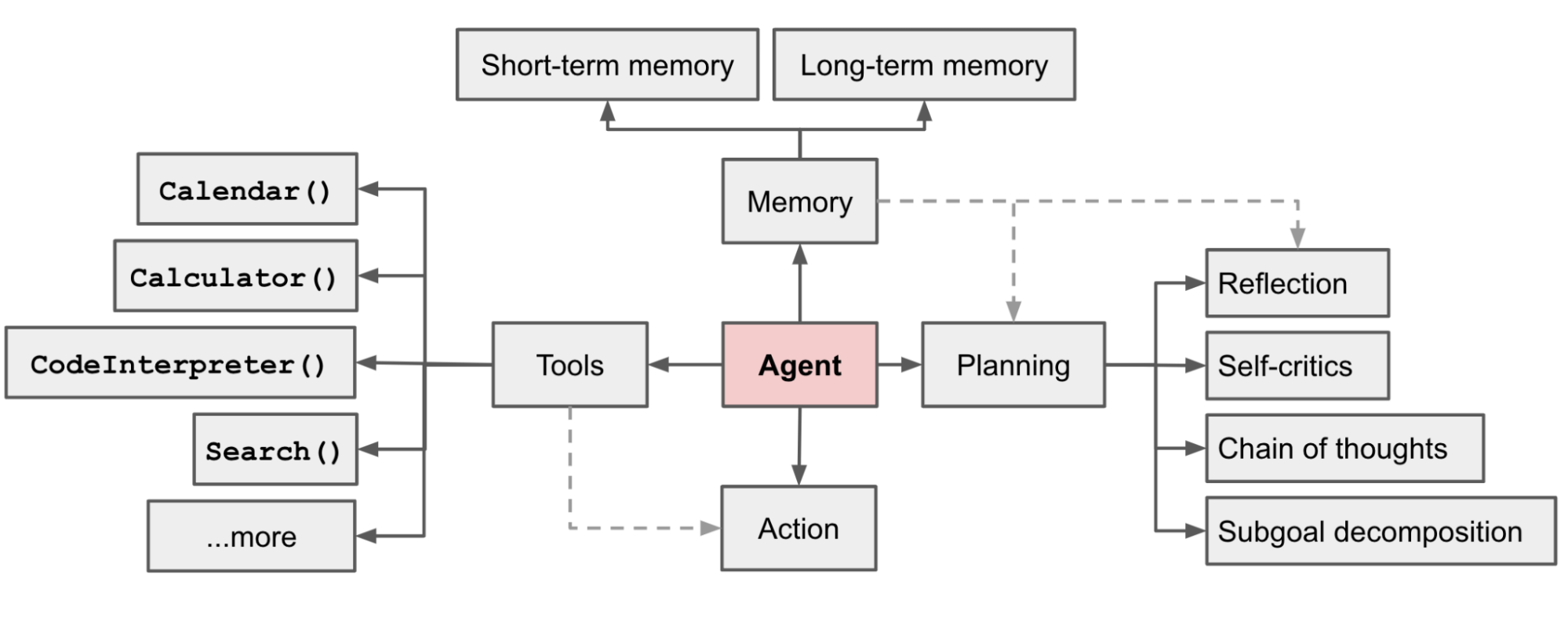
Agent可以用公式定义为:
Agent = LLM + Planning + Action + Tools + Memory
智能体能够实现复杂任务的规划,可以借助外部工具执行每一个步骤,根据执行结果不断调整,并将结果记录存储起来,最终完成任务。拆开来看:
- LLM:LLM作为智能体的大脑,可以实现任务的规划、根据执行结果进行反思。
- Tools:由于LLM本身的局限,借助外部工具赋予智能体双手,可以根据任务步骤做出行动,如查询天气、执行代码、搜索内容。
- Memory:智能体可以记忆过去的经验,这对学习至关重要,可以根据这些先前的经验调整未来的行动。
借助智能体我们可以实现更加智能化、多步骤的任务,相比Workflow具体的执行流是由LLM制定的,并不是人类经验的硬编码。使用Agent可以实现数据分析、智能个人助手、自动运维工具等。
更进一步多智能体(Multi-Agent)可以视为一个智能社会,不同Agent分工协作实现更加复杂的场景,例如一个软件公司包括产品经理 / 架构师 / 项目经理 / 工程师多个智能体,一起协作来实现复杂的软件。当前也有一些多智能体的框架,如MetaGPT、LangGraph等。
局限
- 依赖LLM,
Agent的推理、反思、规划能力都依赖大模型,不同模型效果有差异 - 很难脱离人类单独运行,一些危险操作(修改数据),无法保证
Agent的精确性,需要人类参与 - 复杂性,实现更复杂,尤其是多智能体,很难测试验证
总结
大模型时代,作为开发者我们可以借助大模型的能力实现更加智能的应用,本文介绍了多个大模型的开发级别,从简单的提示词到智能体,每一个级别都有其特点和局限,选择合适的技术来适配不同场景,你也可以转化为一个AI加持的开发者。
展望一下未来,随着AI技术的发展,真正的智能有没有可能实现呢?各种智能体可以替代我们做事,甚至做一些人类做不到的事情。
引用
- https://arxiv.org/html/2401.05459v1
- https://www.promptingguide.ai/
- https://substack.com/@cwolferesearch/note/c-48888444
- https://lilianweng.github.io/posts/2023-06-23-agent/
- https://docs.deepwisdom.ai/
- https://python.langchain.com/
Explore more in https://qingwave.github.io