
· cloud
手写一个Kubernetes CNI网络插件
CNI(Container Network Interface) 即容器的网络 API 接口,在 Kubernetes 中通过 CNI 来扩展网络功能,今天我们从零开始实现一个自己的 CNI 网络插件。
本文所有代码见:
CNI 简介
Kubernetes 提供了很多扩展点,通过 CNI 网络插件可以支持不同的网络设施,大大提供了系统的灵活性,目前也已成为容器网络领域的标准。
Kubernetes 与 CNI 的交互逻辑如下: 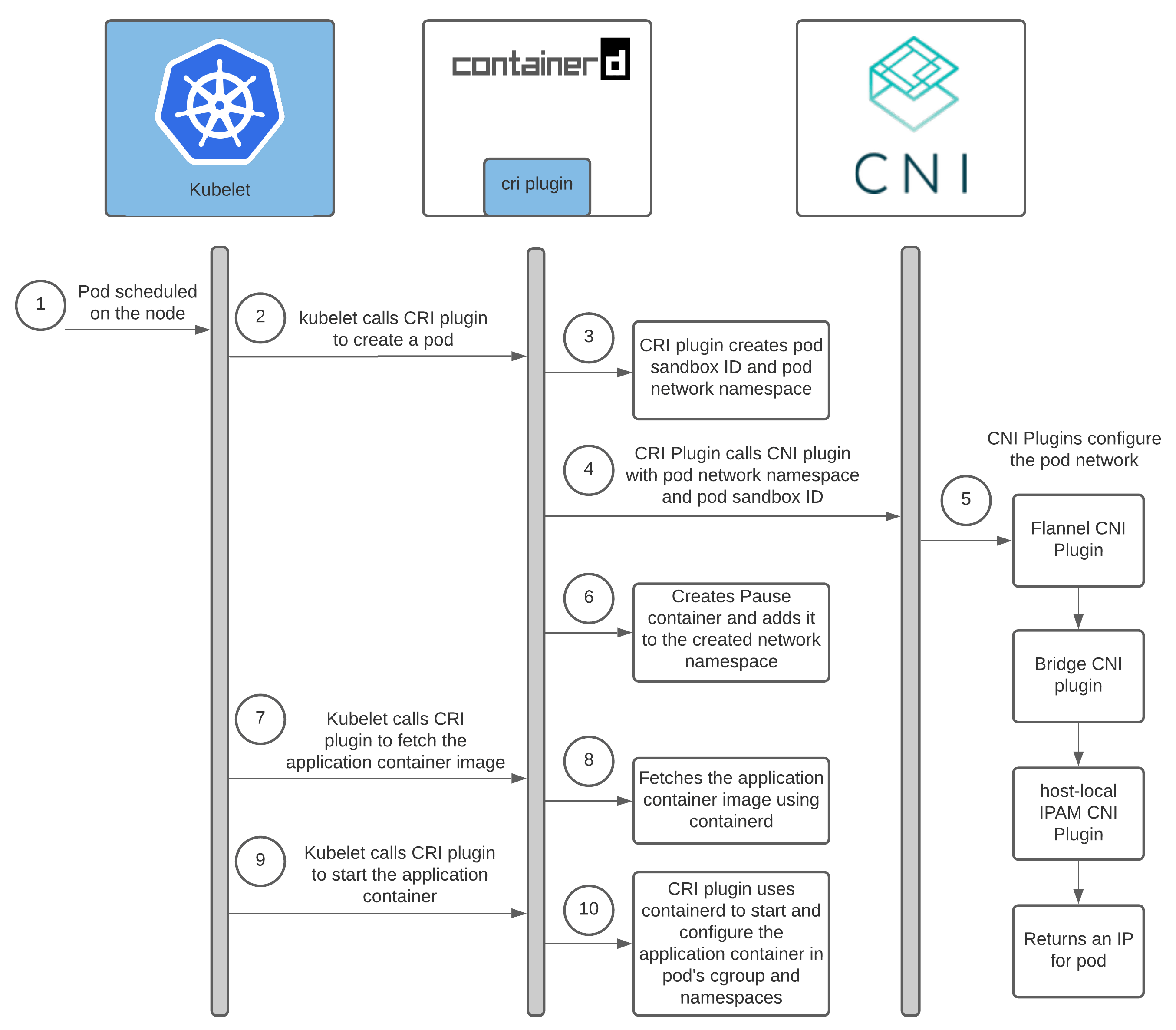
Kubelet 监听到 Pod 调度到当前节点后,通过 rpc 调用 CRI(containerd, cri-o 等),CRI 创建 Sandbox 容器,初始化 Cgroup 与 Namespace,然后再调用 CNI 插件分配 IP,最后完成容器创建与启动。
不同于 CRI、CSI 通过 rpc 通信,CNI 是通过二进制接口调用的,通过环境变量和标准输入传递具体网络配置,下图为 Flannel CNI 插件的工作流程,通过链式调用 CNI 插件实现对 Pod 的 IP 分配、网络配置: 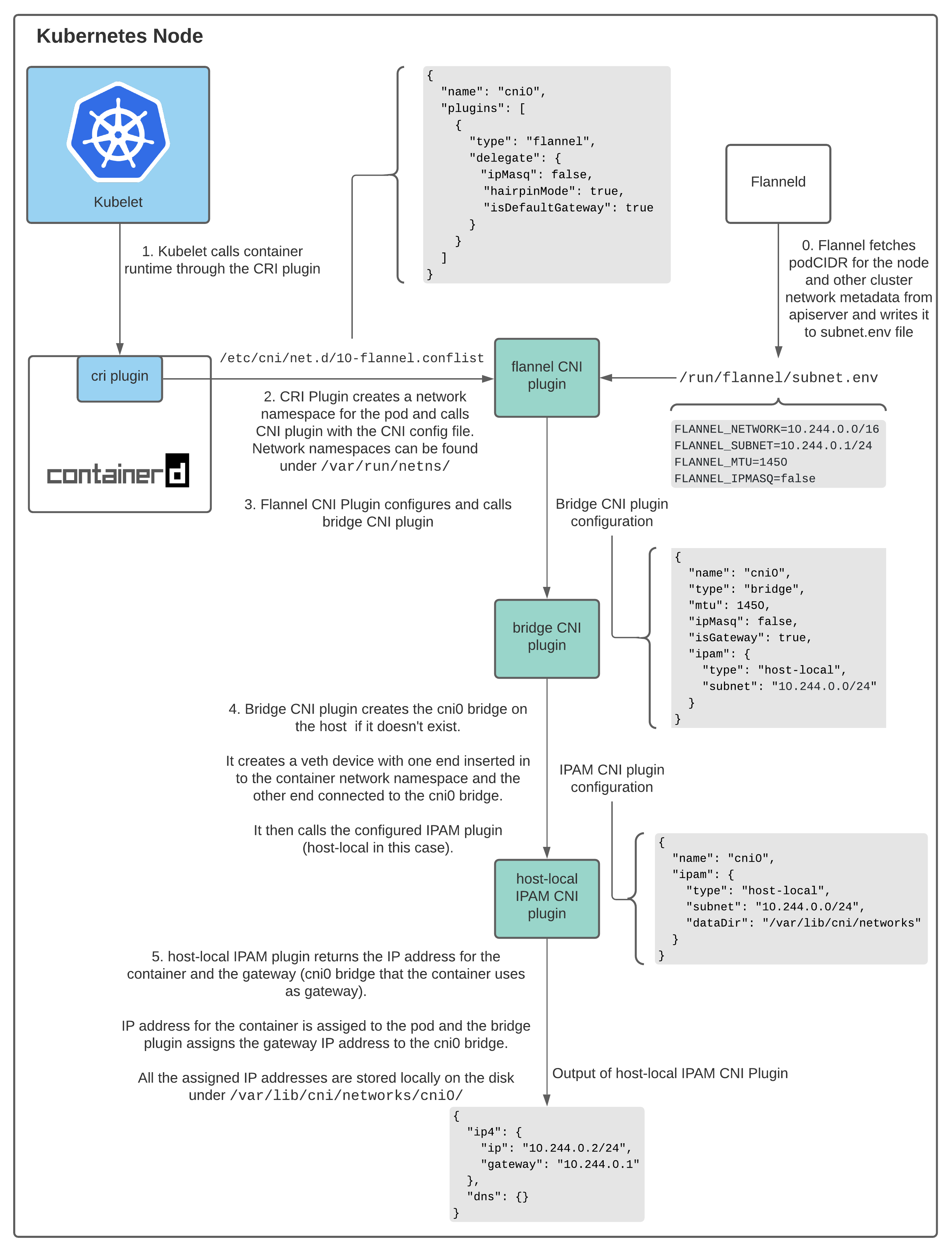
实现 CNI
实现一个完整的 K8s CNI 插件需要满足以下几点要求:
- Pod IP 分配,即 IPAM 功能
- 节点与其上所有 Pod 网络互通,以实现健康检查
- 集群内所有 Pod 可通信,包括同节点与不同节点
- 其他功能的支持,比如 hostPort、兼容 kube-proxy 的 iptables 规则等
我们主要实现前三点需求,通过 Linux Bridge、Veth Pair 以及路由来实现 K8s 网络方案。
网络架构如下: 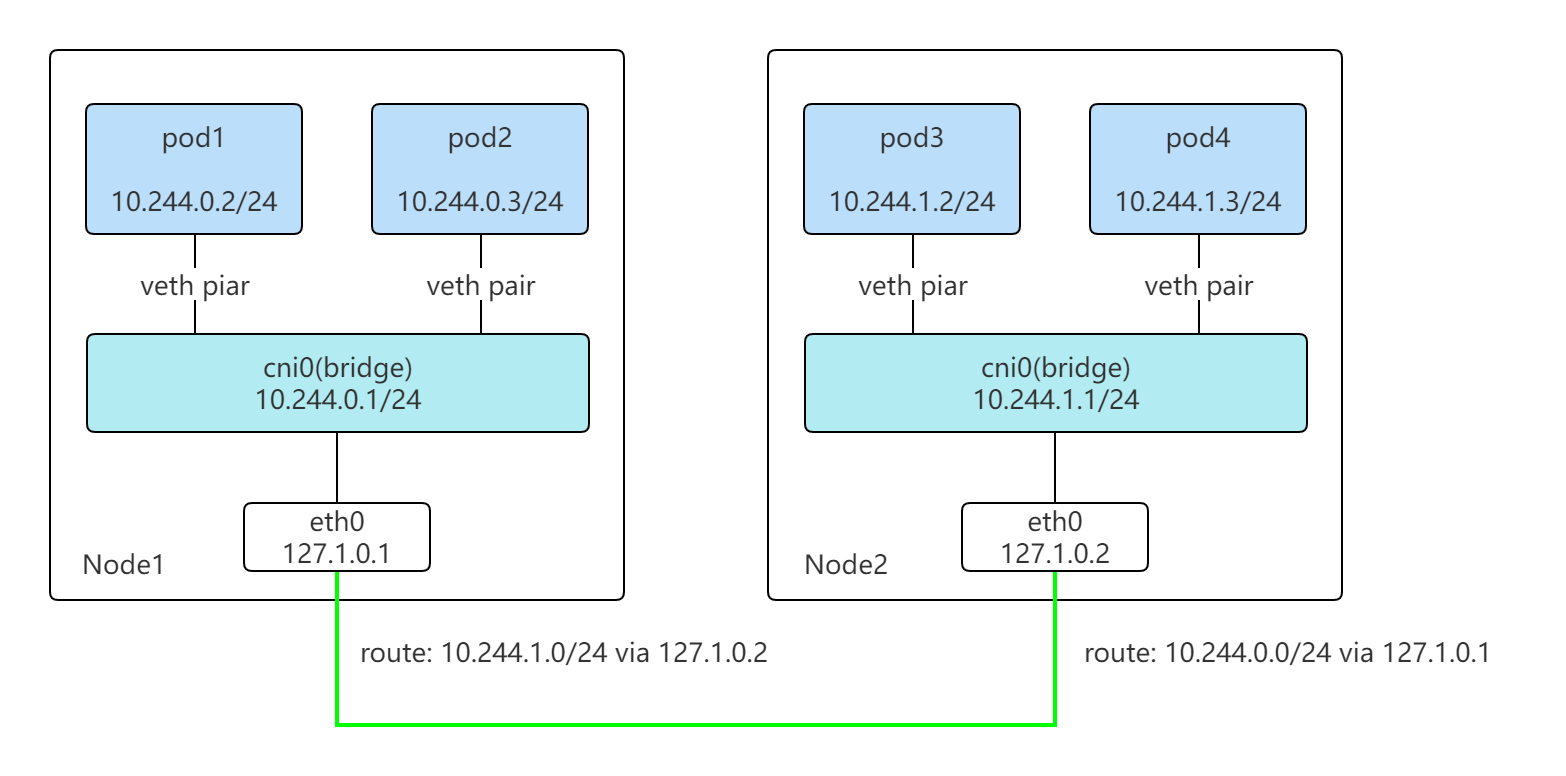
包括两个组件:
- mycni: CNI 插件,实现 IPAM,为 Pod 分配 IP 配置路由,通过网桥实现同节点上不同 Pod 的通信
- mycnid: 节点上守护进程,监听 K8s Node,获取各个节点 CIDR 写入路由
Mycni
CNI 官方已经提供了工具包,我们只需要实现cmdAdd, cmdCheck, cmdDel接口即可实现一个 CNI 插件。
func PluginMainWithError(cmdAdd, cmdCheck, cmdDel func(_ *CmdArgs) error,
versionInfo version.PluginInfo, about string) *types.Error {
return (&dispatcher{
Getenv: os.Getenv,
Stdin: os.Stdin,
Stdout: os.Stdout,
Stderr: os.Stderr,
}).pluginMain(cmdAdd, cmdCheck, cmdDel, versionInfo, about)
}
我们主要关注网络创建过程,实现 IP 分配与网桥配置:
func cmdAdd(args *skel.CmdArgs) error {
// 加载配置
conf, err := config.LoadCNIConfig(args.StdinData)
// 存储本机IP分配列表
s, err := store.NewStore(conf.DataDir, conf.Name)
defer s.Close()
// ipam服务,分配ip
ipam, err := ipam.NewIPAM(conf, s)
gateway := ipam.Gateway()
ip, err := ipam.AllocateIP(args.ContainerID, args.IfName)
// 创建网桥,虚拟设备,并绑定到网桥
br, err := bridge.CreateBridge(conf.Bridge, mtu, ipam.IPNet(gateway))
bridge.SetupVeth(netns, br, mtu, args.IfName, ipam.IPNet(ip), gateway)
// 返回网络配置信息
result := ¤t.Result{
CNIVersion: current.ImplementedSpecVersion,
IPs: []*current.IPConfig{
{
Address: net.IPNet{IP: ip, Mask: ipam.Mask()},
Gateway: gateway,
},
},
}
return types.PrintResult(result, conf.CNIVersion)
}
IPAM
IPAM 服务需要保证为 Pod 分配唯一的 IP,K8s 会为每个节点分配 PodCIDR,只需要保证节点上所有 Pod IP 不冲突即可。
通过本地文件来存储已分配的 IP,当新 Pod 创建时只需要检查已分配 IP,通过 CIDR 取一个未使用的 IP。通常做法是将 IP 信息存储在数据库中(etcd),简单期间本文只使用文件存储。
首先需要保证并发请求时,IP 分配不会冲突,可通过文件锁实现,存储实现如下:
type data struct {
IPs map[string]containerNetINfo `json:"ips"` // 存储IP信息
Last string `json:"last"`// 上一个分配IP
}
type Store struct {
*filemutex.FileMutex // 文件锁
dir string
data *data
dataFile string
}
分配 IP 代码:
func (im *IPAM) AllocateIP(id, ifName string) (net.IP, error) {
im.store.Lock() // 上锁,防止冲突
defer im.store.Unlock()
im.store.LoadData(); // 加载存储中IP数据
// 根据容器id查询ip是否已分配
ip, _ := im.store.GetIPByID(id)
if len(ip) > 0 {
return ip, nil
}
// 从上次已分配IP开始,依次检查,如果IP未使用则添加到文件中
start := make(net.IP, len(last))
for {
next, err := im.NextIP(start)
if err == IPOverflowError && !last.Equal(im.gateway) {
start = im.gateway
continue
} else if err != nil {
return nil, err
}
// 分配IP
if !im.store.Contain(next) {
err := im.store.Add(next, id, ifName)
return next, err
}
start = next
if start.Equal(last) {
break
}
fmt.Printf("ip: %s", next)
}
return nil, fmt.Errorf("no available ip")
}
IP 分配过程如下:
- 加文件锁,读取已分配 IP
- 从上一个分配 IP 开始,遍历判断是否未分配
- 如果 IP 未使用,存储到文件中并返回
节点内通信
节点内通信通过网桥实现,创建一个虚拟设备对,分别绑定到 Pod 所在 Namespace 与网桥上,绑定 IPAM 分配的 IP, 并设置默认路由。从而实现同一个节点上,Node->Pod 与 Pod 之间的通信。
首先,如果网桥不存在则通过 netlink 库创建
func CreateBridge(bridge string, mtu int, gateway *net.IPNet) (netlink.Link, error) {
if l, _ := netlink.LinkByName(bridge); l != nil {
return l, nil
}
br := &netlink.Bridge{
LinkAttrs: netlink.LinkAttrs{
Name: bridge,
MTU: mtu,
TxQLen: -1,
},
}
if err := netlink.LinkAdd(br); err != nil && err != syscall.EEXIST {
return nil, err
}
dev, err := netlink.LinkByName(bridge)
if err != nil {
return nil, err
}
// 添加地址,即Pod默认网关地址
if err := netlink.AddrAdd(dev, &netlink.Addr{IPNet: gateway}); err != nil {
return nil, err
}
// 启动网桥
if err := netlink.LinkSetUp(dev); err != nil {
return nil, err
}
return dev, nil
}
为容器创建虚拟网卡
func SetupVeth(netns ns.NetNS, br netlink.Link, mtu int, ifName string, podIP *net.IPNet, gateway net.IP) error {
hostIface := ¤t.Interface{}
err := netns.Do(func(hostNS ns.NetNS) error {
// 在容器网络空间创建虚拟网卡
hostVeth, containerVeth, err := ip.SetupVeth(ifName, mtu, "", hostNS)
if err != nil {
return err
}
hostIface.Name = hostVeth.Name
// set ip for container veth
conLink, err := netlink.LinkByName(containerVeth.Name)
if err != nil {
return err
}
// 绑定Pod IP
if err := netlink.AddrAdd(conLink, &netlink.Addr{IPNet: podIP}); err != nil {
return err
}
// 启动网卡
if err := netlink.LinkSetUp(conLink); err != nil {
return err
}
// 添加默认路径,网关即网桥的地址
if err := ip.AddDefaultRoute(gateway, conLink); err != nil {
return err
}
return nil
})
// need to lookup hostVeth again as its index has changed during ns move
hostVeth, err := netlink.LinkByName(hostIface.Name)
if err != nil {
return fmt.Errorf("failed to lookup %q: %v", hostIface.Name, err)
}
// 将虚拟网卡另一端绑定到网桥上
if err := netlink.LinkSetMaster(hostVeth, br); err != nil {
return fmt.Errorf("failed to connect %q to bridge %v: %v", hostVeth.Attrs().Name, br.Attrs().Name, err)
}
return nil
}
至此,CNI 插件的功能实现完成。
Mycnid
mycnid为节点上的守护进程,实现不同节点的 Pod 通信,主要功能包括:
- 监听 K8s Nodes, 获取本节点的 PodCIDR 写入配置文件(默认位置在
/run/mycni/subnet.json) - 为其他节点添加路由(
ip route add podCIDR via nodeip) - 一些初始化配置,写入默认的 Iptables 规则,初始化网桥
节点间通信
通过 Controller 监听 Node 资源,当前有节点 Add/Delete 时,调用 Reconcile 同步路由
func (r *Reconciler) Reconcile(ctx context.Context, req reconcile.Request) (reconcile.Result, error) {
result := reconcile.Result{}
nodes := &corev1.NodeList{}
// 获取所有节点
if err := r.client.List(ctx, nodes); err != nil {
return result, err
}
// 获取节点的CIDR,生成路由
cidrs := make(map[string]netlink.Route)
for _, node := range nodes.Items {
if node.Name == r.config.nodeName { // 跳过当前节点
continue
}
// 生成期望路由
_, cidr, err := net.ParseCIDR(node.Spec.PodCIDR)
nodeip, err := getNodeInternalIP(&node)
route := netlink.Route{
Dst: cidr,
Gw: nodeip,
ILinkIndex: r.hostLink.Attrs().Index,
}
cidrs[cidr.String()] = route
// 与本地的路由对比,不存在则创建
if currentRoute, ok := r.routes[cidr.String()]; ok {
if isRouteEqual(route, currentRoute) {
continue
}
if err := r.ReplaceRoute(currentRoute); err != nil {
return result, err
}
} else {
if err := r.addRoute(route); err != nil {
return result, err
}
}
}
// 删除多余的路由
for cidr, route := range r.routes {
if _, ok := cidrs[cidr]; !ok {
if err := r.delRoute(route); err != nil {
return result, err
}
}
}
return result, nil
}
// 创建路由
func (r *Reconciler) addRoute(route netlink.Route) (err error) {
defer func() {
if err == nil {
r.routes[route.Dst.String()] = route
}
}()
log.Info(fmt.Sprintf("add route: %s", route.String()))
err = netlink.RouteAdd(&route)
if err != nil {
log.Error(err, "failed to add route", "route", route.String())
}
return
}
主要步骤包括:
- 当前 Node 变化时获取集群中所有 Node 网络信息(PodCIDR、IP 等)
- 与节点上路由进行比对,若缺少则添加,若宿主机上存在多余的路由则删除
为什么不是直接对变化的 Node 修改对应的路由?
通过获取所有节点网络信息与宿主机进行路由比对,符合 Kubernetes 编程规范,声明式编程而不是过程式,这种方式不会丢事件。即使手动误删了路由,下次同步也会将其恢复。
其他配置
如果使用 Docker 的话,Docker 会禁止非 Docker 网桥的流量转发,需要配置 iptables
iptables -A FORWARD -i ${bridge} -j ACCEPT
大部分集群允许 Pod 访问外部网络,需要配置 SNAT:
sudo iptables -t nat -A POSTROUTING -s $cidr -j MASQUERADE
# 另外允许主机网卡转发
iptables -A FORWARD -i $hostNetWork -j ACCEPT
代码如下,通过github.com/coreos/go-iptables/iptables可以配置 iptables:
func addIptables(bridgeName, hostDeviceName, nodeCIDR string) error {
ipt, err := iptables.NewWithProtocol(iptables.ProtocolIPv4)
if err != nil {
return err
}
if err := ipt.AppendUnique("filter", "FORWARD", "-i", bridgeName, "-j", "ACCEPT"); err != nil {
return err
}
if err := ipt.AppendUnique("filter", "FORWARD", "-i", hostDeviceName, "-j", "ACCEPT"); err != nil {
return err
}
if err := ipt.AppendUnique("nat", "POSTROUTING", "-s", nodeCIDR, "-j", "MASQUERADE"); err != nil {
return err
}
return nil
}
演示
通过 kind 模拟创建多节点 k8s 集群kind create cluster --config deploy/kind.yaml
# cat deploy/kind.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
networking:
# 禁止默认的CNI
disableDefaultCNI: true
nodes:
# 包括一个master节点,三个worker
- role: control-plane
- role: worker
- role: worker
- role: worker
创建完成后,可以看到所有节点都是 NotReady,这是因为我们没有装 CNI
mycni kubectl get no
NAME STATUS ROLES AGE VERSION
kind-control-plane NotReady control-plane,master 37s v1.23.4
kind-worker NotReady <none> 18s v1.23.4
kind-worker2 NotReady <none> 18s v1.23.4
kind-worker3 NotReady <none> 18s v1.23.4
接下编译我们的 mycni 镜像,通过kind load docker-image加载到集群中。
部署 CNI 插件,这里参考了 Flannel 的部署,主要是通过 Daemonset 在每个节点上部署一个 Pod,初始化容器将 mycni 检查二进制文件拷贝到/opt/cni/bin,将配置文件拷贝到/etc/cni/net.d,再启动 mycnid 容器。
kubectl apply -f deploy/mycni.yaml
部署完成后,可以看到所有节点状态变为 Ready。
最后测试 Pod 的网络配置情况,部署一个多副本 Alpine Deployment
kubectl create deployment cni-test --image=alpine --replicas=6 -- top
kubectl get po -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
cni-test-5df744744c-5wthb 1/1 Running 0 12s 10.244.2.3 kind-worker2 <none> <none>
cni-test-5df744744c-7cdll 1/1 Running 0 12s 10.244.1.2 kind-worker <none> <none>
cni-test-5df744744c-jssjk 1/1 Running 0 12s 10.244.3.2 kind-worker3 <none> <none>
cni-test-5df744744c-jw6xv 1/1 Running 0 12s 10.244.1.3 kind-worker <none> <none>
cni-test-5df744744c-klbr4 1/1 Running 0 12s 10.244.3.3 kind-worker3 <none> <none>
cni-test-5df744744c-w7q9t 1/1 Running 0 12s 10.244.2.2 kind-worker2 <none> <none>
所有 Pod 可以正常启动,首先测试 Node 与 Pod 的通信, 结果如下
root@kind-worker:/# ping 10.244.1.2
PING 10.244.1.2 (10.244.1.2) 56(84) bytes of data.
64 bytes from 10.244.1.2: icmp_seq=1 ttl=64 time=0.101 ms
64 bytes from 10.244.1.2: icmp_seq=2 ttl=64 time=0.049 ms
--- 10.244.1.2 ping statistics ---
同节点上的 Pod 通信:
~ kubectl exec cni-test-5df744744c-7cdll -- ping 10.244.1.3 -c 4
PING 10.244.1.3 (10.244.1.3): 56 data bytes
64 bytes from 10.244.1.3: seq=0 ttl=64 time=0.118 ms
64 bytes from 10.244.1.3: seq=1 ttl=64 time=0.077 ms
64 bytes from 10.244.1.3: seq=2 ttl=64 time=0.082 ms
64 bytes from 10.244.1.3: seq=3 ttl=64 time=0.085 ms
--- 10.244.1.3 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 0.077/0.090/0.118 ms
不同节点的 Pod 通信
~ kubectl exec cni-test-5df744744c-7cdll -- ping 10.244.2.2 -c 4
PING 10.244.2.2 (10.244.2.2): 56 data bytes
64 bytes from 10.244.2.2: seq=0 ttl=62 time=0.298 ms
64 bytes from 10.244.2.2: seq=1 ttl=62 time=0.234 ms
64 bytes from 10.244.2.2: seq=2 ttl=62 time=0.180 ms
64 bytes from 10.244.2.2: seq=3 ttl=62 time=0.234 ms
--- 10.244.2.2 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 0.180/0.236/0.298 ms
Pod 访问外网
~ kubectl exec cni-test-5df744744c-7cdll -- ping www.baidu.com -c 4
PING www.baidu.com (103.235.46.39): 56 data bytes
64 bytes from 103.235.46.39: seq=0 ttl=47 time=312.115 ms
64 bytes from 103.235.46.39: seq=1 ttl=47 time=311.126 ms
64 bytes from 103.235.46.39: seq=2 ttl=47 time=311.653 ms
64 bytes from 103.235.46.39: seq=3 ttl=47 time=311.250 ms
--- www.baidu.com ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 311.126/311.536/312.115 ms
通过测试验证,我们实现的 mycni 满足 k8s 的 CNI 网络插件的要求,可以实现集群内所有 Pod 的通信,以及 Node 与 Pod 的通信,Pod 也可以正常访问外网。
总结
本文首先介绍了 CNI 的架构,通过手动实现一个 CNI 网络插件,可以更加深入的了解 CNI 的工作原理以及 Linux 相关网络知识。
欢迎指正,所有代码见:
引用
- https://www.cni.dev/docs/
- https://ronaknathani.com/blog/2020/08/how-a-kubernetes-pod-gets-an-ip-address/
Explore more in https://qingwave.github.io